我的数据体系
本文最后更新于 2024年3月9日 晚上
结合自己的数据生涯,构建数据体系知识,希望可以让数据流动起来,创造出更多的价值。
背景知识
什么是大数据:
数据量大(Volume)
数据类型繁多(Variety)
处理数据快(Velocity)
价值密度低(Value)
如何处理并从中发掘价值:
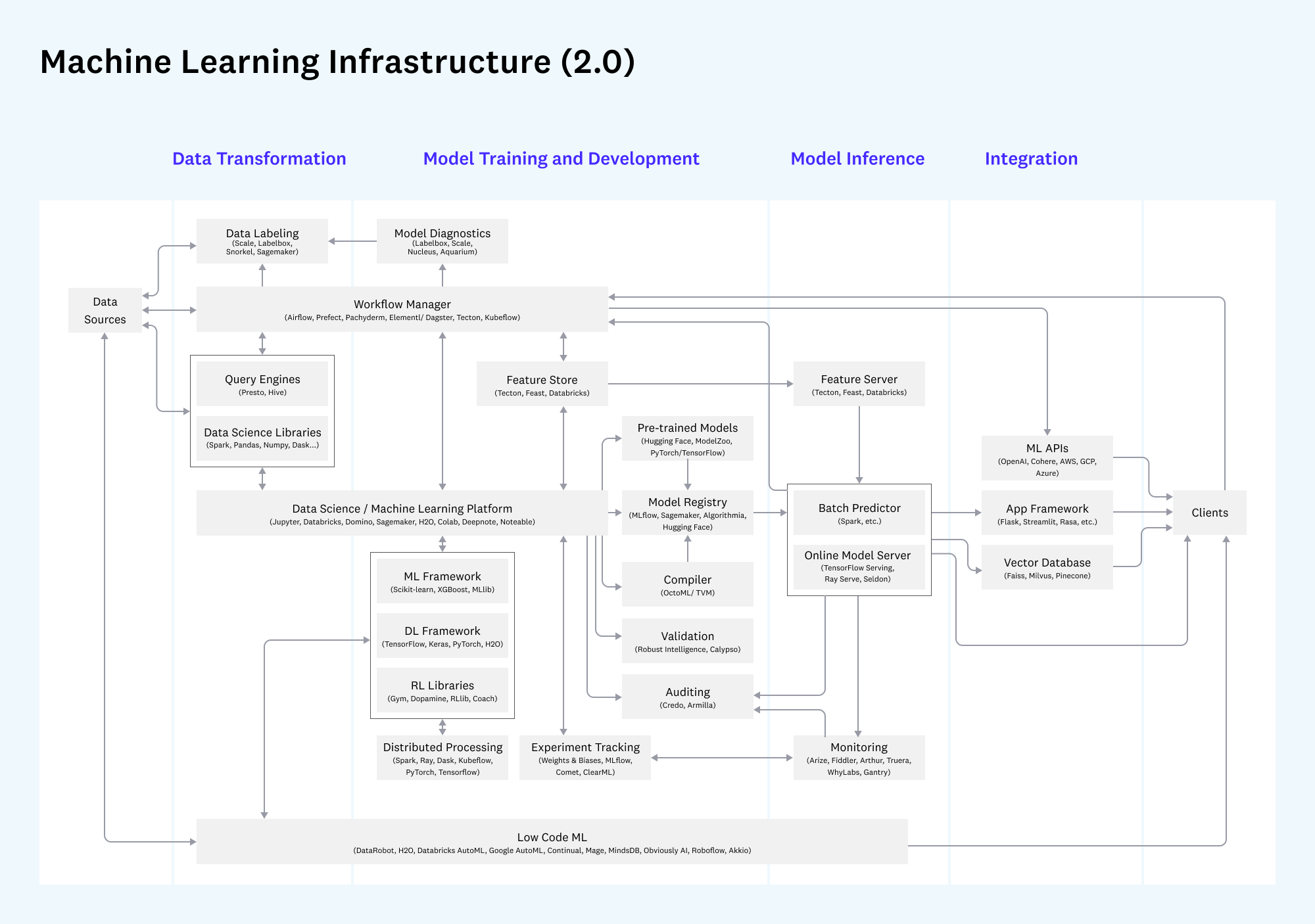
基础设施:存储&计算&调度&运维
平台服务:降低开发门槛
应用开发:创造业务价值
从一个需求开始
需求:交易转化漏斗
需求分析
定义漏斗阶段:点击商品 -> 创建订单 -> 订单支付 -> 支付成功
设定北极星指标:转化率&转化时间
数据采集:数据源
客户端:api 上传
服务端:日志采集
数据库:binlog
外部引入:爬虫
数据开发
技术:SQL Is All Your Need

数仓分层:更好地管理和组织数据
ODS:异构数据源入仓
DWD:不同阶段串联明细
DWS:用户粒度聚合
ADM:转化漏斗&时间等指标
数据运维
补数:全增量一体&更新
质量:SLA
成本:计算&存储
合规&安全:隐私计算
数据服务:看数 -> 决策-> 洞察
看板:转化漏斗图(OLAP + BI)
标签:支付画像(KV)
特征&样本:Feature Store
监控:转化波动(Message)
数据价值:策略 -> 效果
- AB实验:控制变量提高转化率
问题
需求管理
一个需求 -> 一类需求
业务建模
业务过程
业务对象
维度建模
维度表
事实表
指标建模
原子指标:aggregation
业务限定:filter
统计粒度:group by
统计周期:window
需求背后真正的问题以及更大的问题
团队 -> 部门 -> 公司 -> 国家
团队协作:思考问题不能有边界,但需要明确分工
底层技术
数据密集型应用系统:数据库组件 -> 数据流应用系统
分布式系统: CAP理论
数据复制
数据分区
分布式事务:宽松式约束,事后进行修复
一致性与共识
数据模型 + 声明式查询语言(SQL)
关系模型
文档模型
图数据模型
存储
索引:LSM-Tree vs B-Tree
OLTP vs OLAP
文件(对象) vs 消息
计算
MapReduce -> 超越MapReduce
流计算 vs 批计算 -> 批计算为流计算的特例
Hadoop vs MPP
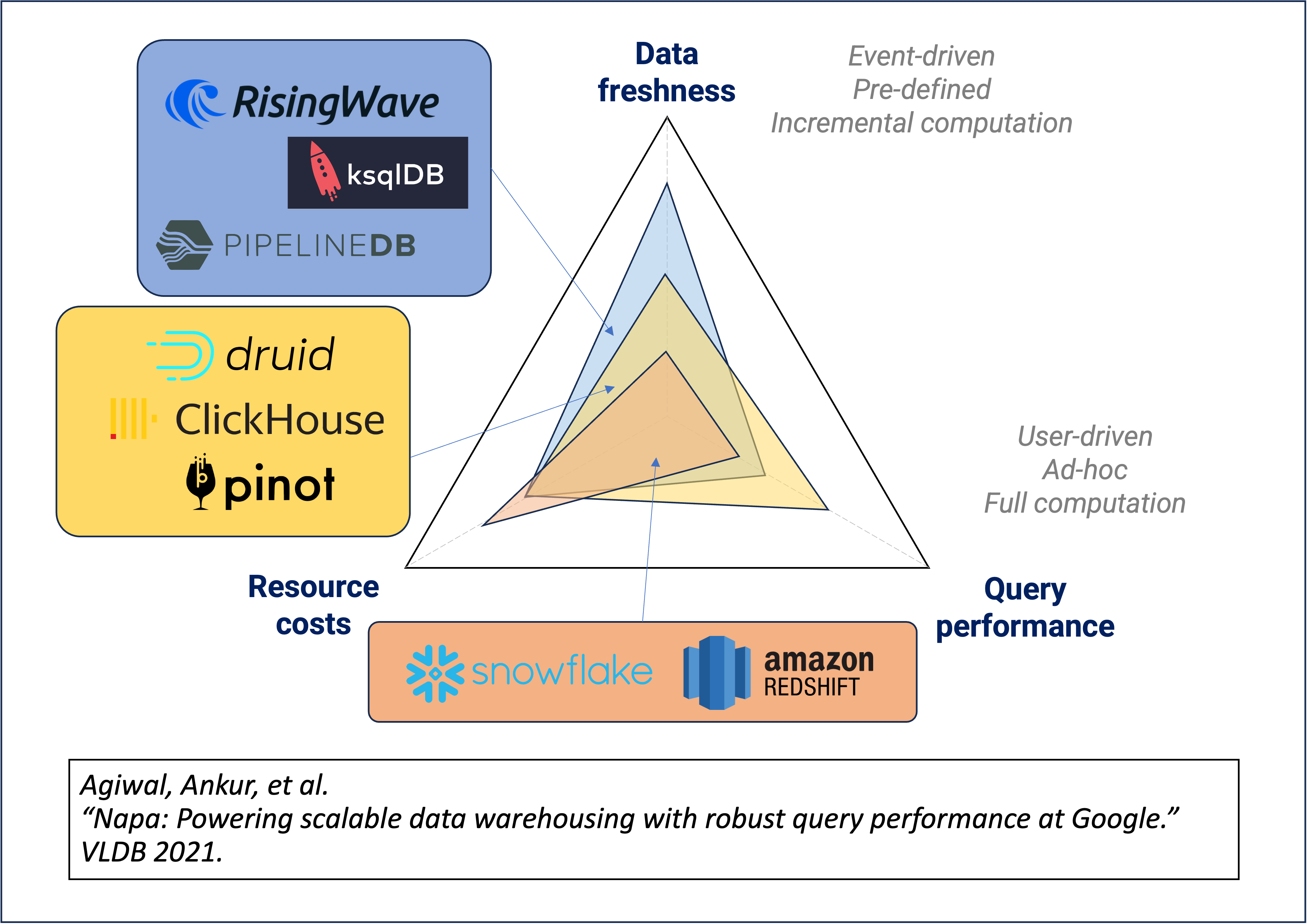
技术发展
- 技术成熟度

- 湖仓一体:准实时

Data&AI
DataOps: 重塑开发工作流
DCAI: 数据驱动模型效果提升